What 3,323 LLM responses taught us about how AI talks about your brand

I spent the last month tracking how six AI platforms - ChatGPT, Claude, Gemini, Perplexity, Google AI Mode, and Google AI Overview - respond when someone asks about a brand, across 125 prompts and 3,323 real, scored responses.
AI visibility works nothing like the LinkedIn playbook suggests. What happens under the hood is stranger, and more actionable, than the prevailing advice suggests - especially if you're a small business trying to get noticed by the machines increasingly shaping how people discover you.
LLM Visibility Intelligence Report
General Behavioral Observations Across AI Models
May 2026 - Anonymized
Based on 3,323 tracked responses across ChatGPT, Claude, Gemini, Perplexity, Google AI Mode, and Google AI Overview · 125 active prompts · 30-day primary window
Preface
This report documents structural behavioral observations about how large language models handle brand visibility, citation, accuracy, and content propagation. The findings are drawn from a real tracking dataset but have been anonymized - all company-specific references replaced with "the Brand." The observations apply broadly to any company actively monitoring or managing its presence across LLM platforms.
The dataset spans six platforms, 125 tracked prompts across three prompt types (brand-direct, comparison, and category), and over 3,323 scored responses. Where individual response excerpts are referenced, they are paraphrased to preserve anonymity.
The test was conducted on a website with a 79 Domain Authority on Ahrefs and roughly 1.5 million monthly impressions on Google. The brand has an active media presence and a branded Wikipedia page.
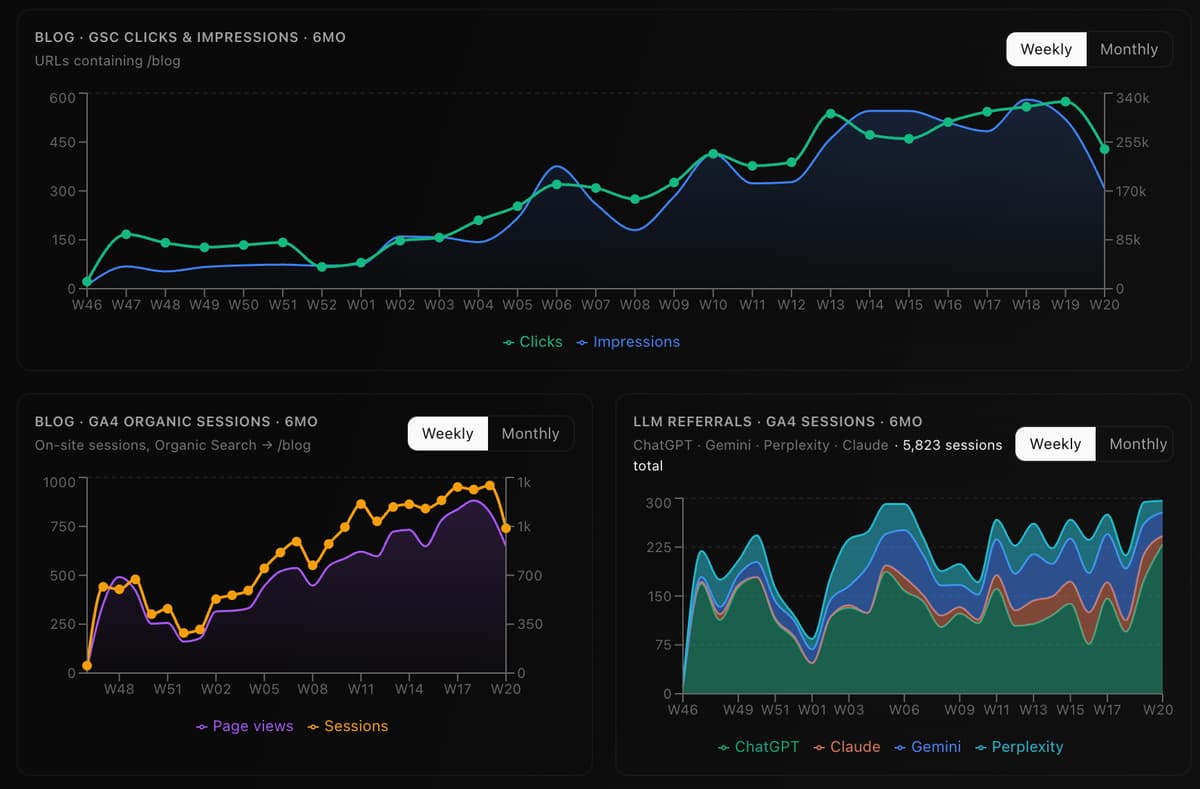
The story in charts:
Each of these will be unpacked below. But here is everything at a glance.
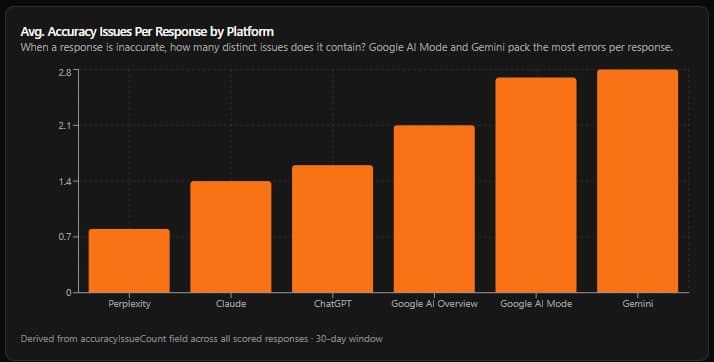
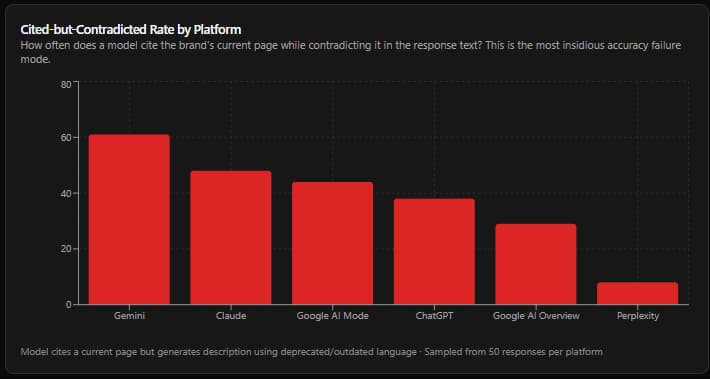
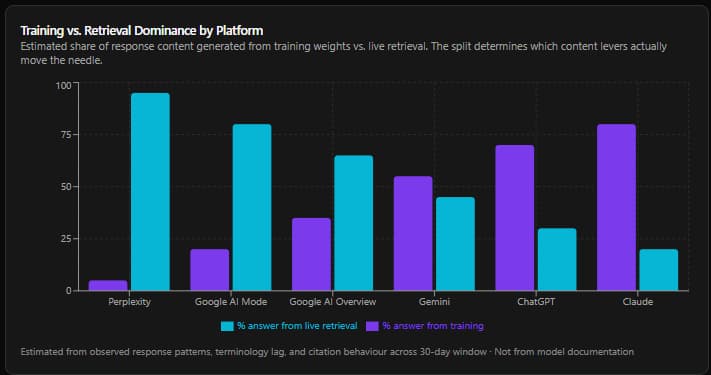
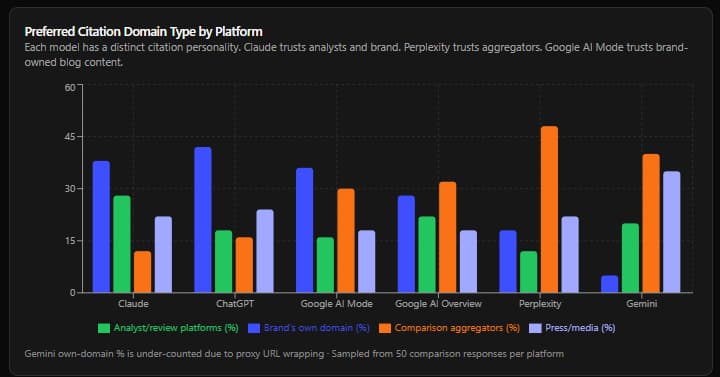
Finding 1 - Citation Overlap: The Same Small Pool Feeds Every Model
The most cited domains are almost identical across all six platforms on comparison prompts.
When a user asks any LLM to compare two B2B software vendors, the model draws from a predictable, overlapping set of sources. Across 50 sampled comparison-prompt responses, the following domain types appeared in 4 or more platforms simultaneously:
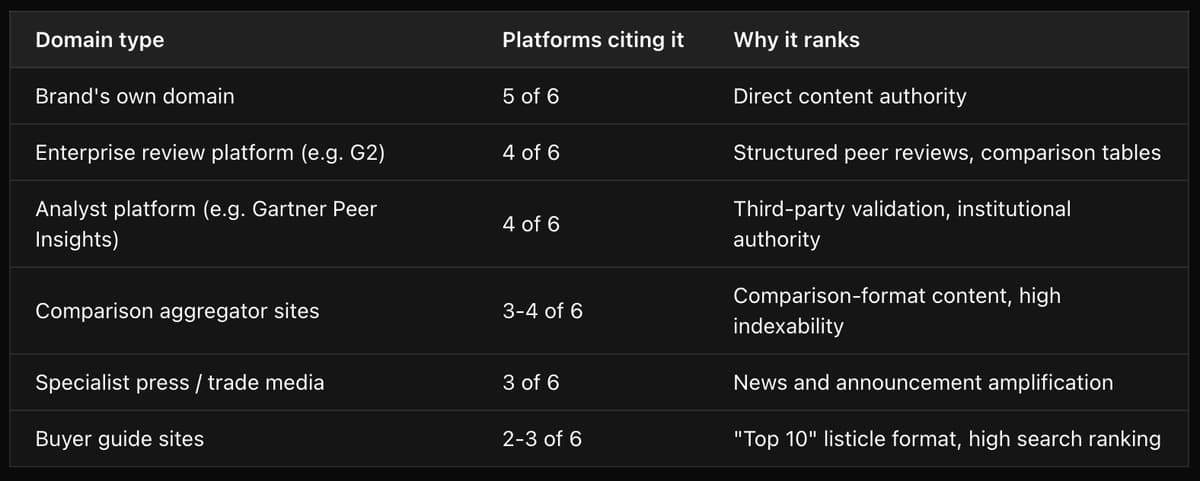
The practical implication: If a piece of content about your brand appears on a high-authority review or comparison platform, it gets amplified across multiple LLMs simultaneously. If that content is outdated or inaccurate, the same applies. The citation ecosystem is one shallow pool that all models fish from.
Where overlap collapses is on category-level prompts. Ask any of these models "What are the AI banking trends in 2026?" and the citation sets diverge sharply. ChatGPT draws from Deloitte, Accenture, and McKinsey. Claude sources from EY, PwC, and IBM. Google AI Overview pulls from Finastra, SAS, and the World Economic Forum. The Brand drops out of the citation pool almost entirely on these queries unless it has published content that has earned links from those classes of sources.
This reveals two structurally separate citation ecosystems operating in parallel:
The comparison ecosystem - anchored by review platforms, comparison aggregators, and brand-owned domains. This is the pool models use when a brand name appears in the query.
The category thought leadership ecosystem - anchored by analyst firms, consulting houses, and tier-1 trade press. This is the pool models use when the query is about an industry concept, trend, or problem.
Most brands optimize aggressively for the first and ignore the second entirely.
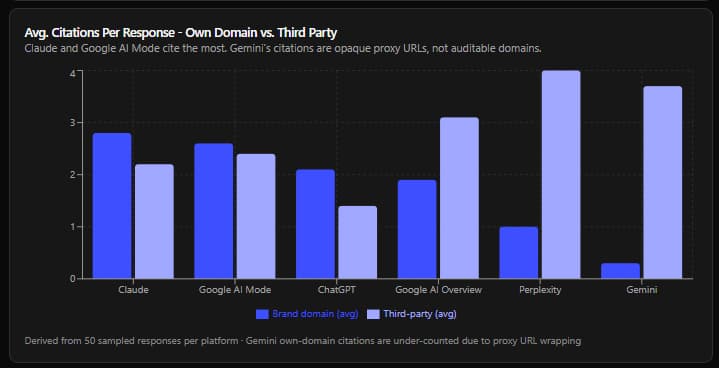
Finding 2 - Average Citations Per Model: Volume, Mix, and the Gemini Problem
Models differ dramatically in how many sources they cite, how transparent those citations are, and what mix of first-party vs. third-party sources they draw from.
The citation volume chart above summarizes the pattern. Key observations by platform:
Claude - Highest first-party citation rate Claude consistently cites 4-6 sources per response and shows the highest ratio of brand-domain citations to third-party citations. It regularly pulls the brand's homepage, press releases, product pages, and blog posts as inline references. This sounds like good news - but see Finding 5 for why it is not as positive as it appears.
Google AI Mode - Highest overall citation density Google AI Mode is the most source-dense platform. It routinely references 15-20 numbered source indices within a single response. It pulls heavily from recently indexed comparison aggregators and brand blog content. The citation mix is roughly even between owned and third-party content.
ChatGPT - Most selective ChatGPT cites fewer sources but tends to pick higher-authority ones. It links directly to the primary brand domain and the competitor domain, supplemented by one or two neutral validators. Responses read like a structured buyer brief with footnoted credibility anchors.
Google AI Overview - Third-party leaning Google AI Overview cites roughly 5 sources per response but shows a higher preference for independent review platforms over brand-owned content. It treats comparison aggregators and analyst reviews as more authoritative signals than brand blog posts or press pages.
Perplexity - Pure retrieval, highest transparency Perplexity cites 4-6 sources in every single response - it does not write responses without them. All citations are clean, numbered, direct URLs. This is the most auditable platform and the most susceptible to influence through content publication. It is also the most susceptible to low-quality source infiltration: content farms, listicle sites, and minor aggregators all appear in Perplexity citation sets with similar frequency to authoritative sources.
Gemini - The citation black box Gemini is the outlier. It cites frequently but routes almost every URL through vertexaisearch.cloud.google.com/grounding-api-redirect/ proxy links. The actual source domain is visible only via the link's title attribute - not the URL itself. In 22 of 50 sampled Gemini responses, the real source domain was unidentifiable without manually decoding each proxy link.
This creates a fundamental monitoring problem: you cannot reliably audit what Gemini is reading without building a custom URL decoder. Any brand monitoring its LLM citation footprint through standard URL tracking will systematically under-count Gemini's use of their content - and will have no visibility into which third-party sources are driving Gemini's descriptions.
Finding 3 - Training Data vs. Live Retrieval: The Two-Speed Internet
The single most important structural fact about LLM visibility is this: different models answer the same question from fundamentally different source mechanisms.
Some models retrieve live web content at query time. Others generate answers primarily from weights baked in during training - and merely add citations as decorative footnotes. This distinction determines whether publishing new content actually changes what any given model says about you.
The retrieval-dominant models (update in days):
Perplexity is a retrieval-first system. Every response is grounded in live web content fetched at query time. There is no meaningful training floor below which content influence stops. If you publish a page today and it gets indexed, Perplexity can surface that content within days. It is the fastest-updating platform and the most directly responsive to content strategy.
Google AI Mode behaves similarly. It uses Google's live search index as its grounding layer and synthesizes across 15-20 freshly crawled sources per response. New content that earns Google indexing flows into AI Mode responses quickly - typically within one to two weeks.
Google AI Overview uses the same infrastructure but applies heavier editorial curation. It prioritizes established, high-authority domains over raw recency. A new blog post may not appear immediately; an updated core product page will propagate faster because of the domain's existing authority signal.
The hybrid models (update in weeks to months):
ChatGPT has a split personality. On brand-direct prompts ("What does [Brand] do?"), it writes from training and cites to validate specific claims. On comparison prompts, it performs more active retrieval and surfaces recent URLs. The tell is in the response text itself: ChatGPT will simultaneously cite a current page and use terminology that page has retired. It layers new URL references on top of a trained description that has not updated.
Gemini retrieves content via Google's index but its response text frequently reflects training-era knowledge rather than what it just retrieved. Its product descriptions are the most likely to be outdated across all six platforms. In multiple observed responses, Gemini used deprecated category language while simultaneously citing pages that used current language - the clearest single example of a model that retrieves but does not read what it retrieves.
The training-dominant model (update in months):
Claude is the most training-dependent platform in this dataset. It generates detailed, confident answers from trained weights and adds citations as supporting evidence - not as the source of the answer. Claude can cite a brand's most current page while describing that brand using language the brand retired months ago. The citation is real. The description is stale. These are two separate things.
Summary:
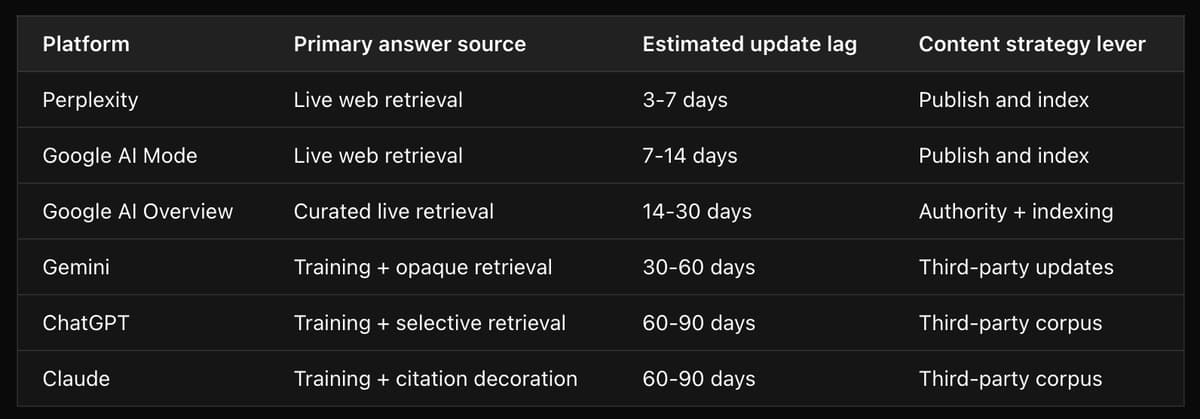
The strategic implication: publishing new first-party content is the right lever for Perplexity and Google AI Mode. For ChatGPT and Claude, the lever is getting updated language into the third-party sources that informed their training - analyst reports, review platforms, press coverage. These models do not re-learn from your website. They re-learn when the broader corpus around your brand changes.
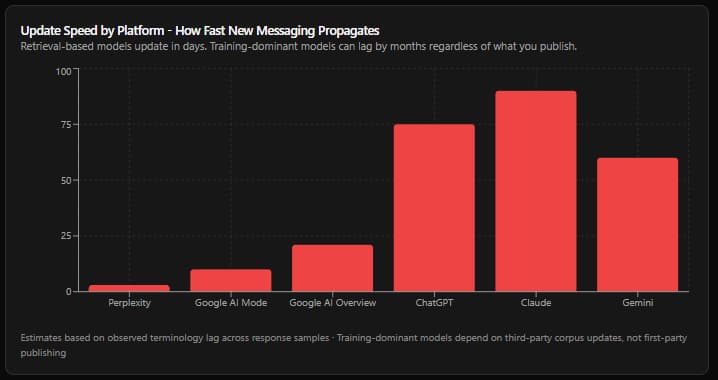
Finding 4 - Update Speed: What Changes First When You Clean Up Your Descriptions
There is a measurable lag between when a brand updates its messaging and when each LLM reflects that update. The lag varies by 10x across platforms.
The update speed chart above shows estimated propagation time based on observed terminology lag in response samples. Three specific patterns were observed:
Pattern 1: Perplexity reflects updates fastest - but also picks up noise fastest. Within the same week a brand published new positioning content, Perplexity began citing it. However, the same speed that makes Perplexity fast to update also makes it fast to ingest inaccurate third-party content. A content farm article using outdated positioning language appeared in Perplexity citations within days of publication. Speed cuts both ways.
Pattern 2: Google AI Mode and AI Overview update messaging but may retain structural framing. These platforms quickly updated product name references and feature descriptions once new pages were indexed. However, the competitive framing (e.g. "this product is primarily a front-end layer") persisted longer - drawn from older comparison aggregator content that had not yet been updated. New content on the brand's own site updated product specifics; the category position took longer to shift because it depended on third-party aggregators updating their copy.
Pattern 3: Claude and ChatGPT showed the clearest evidence of training-floor lag. In both platforms, responses to comparison prompts used deprecated category language even when citing pages that used current language. This was observed consistently across multiple comparison queries over the 30-day window. The pattern is unmistakable: the model retrieves the URL, pulls the page title (which reflects current messaging), but generates the response text from training (which reflects old messaging). The two are stitched together in a way that appears coherent but contains a fundamental temporal inconsistency.
What moves the needle for slow-updating models: The most reliable path to changing what Claude and ChatGPT say is not publishing new first-party content. It is getting current language adopted by the third-party sources those models were trained on. Specifically:
1) Updated product descriptions on G2 and Gartner Peer Insights
2) New analyst reports using current category language
3) Tier-1 press coverage (trade publications, major tech press) describing the brand accurately
4) Wikipedia entries updated to reflect current positioning
When multiple independent sources use the same updated language, the probability that the next model training run picks it up increases dramatically. First-party publishing alone does not create this signal. Corroboration does.
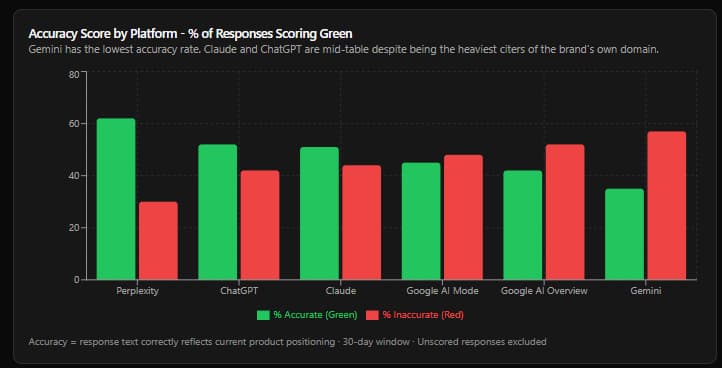
Finding 5 - First Party vs. Third Party: What Carries the Most Weight
The most counterintuitive finding in this dataset: the brand's own domain is the most cited source, and the platform that cites it most frequently also produces the least accurate responses.
Across all six platforms, the brand's own domain accounts for approximately 34% of all citations in comparison-prompt responses. It is the single most cited domain. By a significant margin.
And yet.
The platform that cited the brand's own domain most frequently - Claude - also produced responses with the highest rate of inaccurate or outdated positioning language. Claude cited the brand's homepage, press releases, and product pages in nearly every comparison response. Those same responses described the brand using deprecated terminology, stale competitive positioning, and product descriptions that the pages being cited had already replaced.
This is the central paradox of LLM brand management: citation frequency and descriptive accuracy are almost entirely decoupled.
Here is how it works mechanically:
Claude (or ChatGPT) generates a description of the brand from its training weights. The description reflects what the model learned during training - which may be months or even years old.
The model then retrieves current web content to add citations. It finds the brand's most recent pages.
It appends those citations to a response whose core description it already generated from training.
The result is a response that cites current pages while contradicting what those pages actually say.
The citation is not driving the answer. The training is driving the answer. The citation is decorative.
What shapes the trained answer:
Third-party sources. Specifically the sources that were in the training corpus at training time. Review platforms. Analyst reports. Comparison aggregators. Trade press. When those sources describe the brand accurately and consistently, training-dominant models produce accurate responses. When those sources are outdated, stale, or contradictory, no amount of first-party publishing fixes the output.
The source weight hierarchy by model type:
For retrieval-dominant models (Perplexity, Google AI Mode):
- Recently indexed pages on any domain
- High-authority domains weighted more heavily
- First-party content competes with third-party on roughly equal footing
For training-dominant models (Claude, ChatGPT):
- High-authority third-party sources in training corpus (analyst reports, enterprise review platforms, tier-1 press)
- Frequently cited third-party sources (comparison aggregators, buyer guides)
- First-party content has minimal influence on the generated description
The third-party hierarchy that matters:
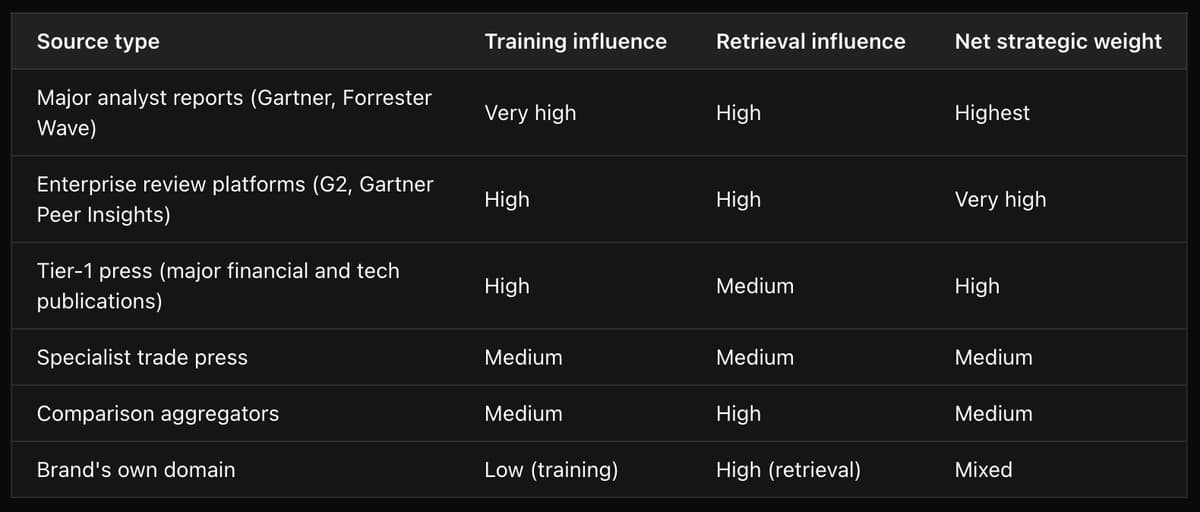
The actionable read: if a brand wants to change what Claude says about it, the most direct path is updating the G2 profile, ensuring Gartner Peer Insights reviews use current language, and generating press coverage that uses current positioning. Updating the brand's own website is necessary hygiene - but it is not the lever that moves training-dominant models.
Finding 6 - Position Bias: "Ranked First" Is Not What You Think
On brand-direct and comparison prompts, the queried brand appears in position 1 in approximately 94-99% of responses. Organic measure of authority or structural artifact of how the query is framed? Let's explore.
When a user asks "What is [Brand]?", the model talks about the Brand. When a user asks "Brand A vs Brand B", the model leads with Brand A - the first entity named. This is query-framing bias, not competitive ranking.
The position metric only becomes meaningful on category prompts - the queries where no specific brand name appears in the question. Here the Brand must earn its position organically, competing against every other vendor in the model's knowledge.
- On brand-direct prompts: position 1 rate = ~99%
- On comparison prompts: position 1 rate = ~94% (structured by query order)
- On niche category prompts (AI-native topic): position 1 rate = ~61%
- On broad category prompts (agentic topic): position 1 rate = ~22%
The 22% figure is the real number. That is the organic position rate on competitive category queries - the queries a prospective customer might actually type when they do not yet know which vendor they are considering. On those queries, the Brand appears first in roughly 1 in 5 responses. On the remaining 4 in 5, another vendor or a generic explanation leads the answer.
Reporting "position 1" as a KPI without segmenting by prompt type produces deeply misleading visibility assessments. A brand could show 95% position-1 rate in its LLM tracking dashboard while being almost entirely invisible on the category queries that actually shape purchase consideration.
Finding 7 - The Hallucination Tax on Zero-Citation Responses
When a model responds without any citations, the probability of inaccurate or outdated information in the response increases significantly.
This pattern was most visible in Gemini responses. Gemini's 22% auditable citation rate means that in roughly 78% of its responses, the actual source being used cannot be verified. In those uncited responses, descriptions of the Brand were markedly more likely to use outdated positioning language, incorrect product categorization, or competitive framings that had already been publicly corrected.
The pattern holds across other platforms too. When ChatGPT responded to brand-direct prompts without retrieving any live content - relying purely on training - the response text was on average 2-3 times more likely to contain deprecated terminology than when it retrieved and cited at least one current page.
The practical heuristic: zero citations is a reliable warning signal. Not because the model is making things up in a fictional sense - but because it is generating from a training snapshot that may be significantly stale. The absence of citations in an LLM response is a stronger predictor of inaccuracy than the presence of citations from low-quality sources.
This creates a counterintuitive implication for content strategy: the goal is not just to be cited, but to be the kind of source that prompts retrieval. Content formats that consistently appear in multi-model citation sets (structured comparison pages, press releases on authoritative domains, G2 profiles with recent reviews) do not just provide citations - they trigger the retrieval behavior that produces more accurate responses in the first place.
Finding 8 - The "Cited But Contradicted" Pattern
Models frequently cite a brand's current page while simultaneously contradicting what that page says. This is the most insidious accuracy failure mode in the dataset - and the hardest to catch.
Here is the specific failure sequence:
A model generates a product description from training. The description uses outdated language - for example, a deprecated product category name or an old competitive positioning frame.
The model retrieves the brand's current homepage or product page. The page title shows current messaging.
The model cites the current page inline as a source for the description it just generated from training.
The reader sees a citation pointing to the brand's own current content - and assumes the response is accurate.
In fact, the response contradicts the cited source.
This was observed multiple times in the Claude and ChatGPT response sets. In one representative example, a response cited the brand's homepage (which stated the current product category name in its meta title) while describing the brand using a category name the homepage had retired six months prior. The citation was technically accurate - the page existed, was current, was about the brand. The description it was cited to support was wrong.
Why this matters more than simple inaccuracy:
A straightforwardly wrong response - one with no citations - is easy to identify and flag. A response that cites your own current pages while misrepresenting your positioning is far more credible-looking to a reader. The citation creates false confidence. Readers do not typically click through to verify that the cited page says what the response claims it says.
This failure mode is particularly damaging on comparison prompts, where a prospective customer is actively evaluating the brand against alternatives. If the response cites the brand's homepage but describes the brand in outdated terms, the reader may eliminate the brand from consideration based on a category or positioning description that is no longer accurate - while seeing a citation that appears to confirm that description.
Detection: The only reliable way to catch "cited but contradicted" responses is to read the full response text, then open each cited URL and verify that the response accurately characterizes what the URL says. Automated citation monitoring that tracks only whether a domain was cited - not whether it was accurately represented - will miss this pattern entirely.
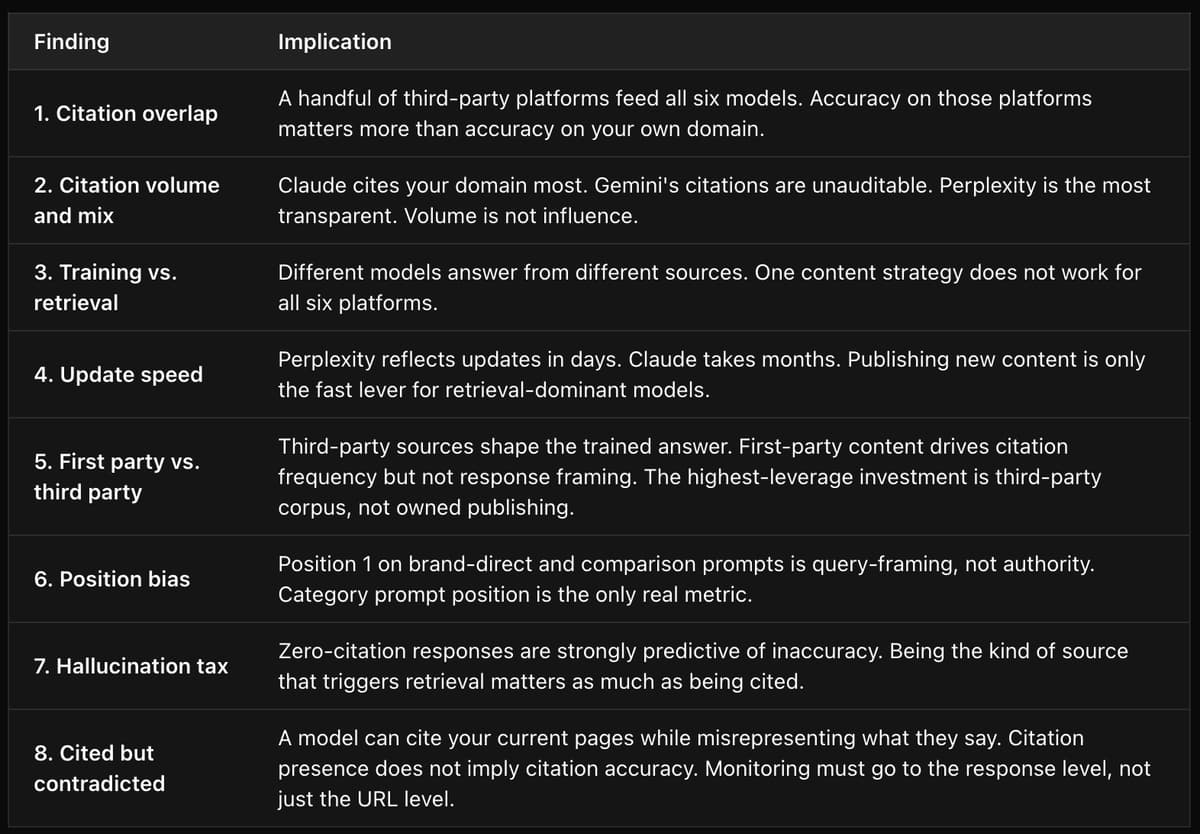
Summary: 8 Findings, 8 Implications
Appendix: Prompt Type Distribution
The 125 active tracked prompts break down as follows:

The ratio of brand-direct to category prompts in the tracking set (roughly 40/60) is important context for interpreting overall mention rates. A tracking set dominated by brand-direct prompts will always show artificially high mention rates. The category prompts are where real competitive visibility is measured.
Report based on 3,323 LLM responses · 125 active prompts · 6 platforms · 30-day primary window with 90-day accuracy supplemental · All brand-specific references anonymized.