The non-commodity content playbook: how to force your AI to write what no one else is saying
AI made commodity content the easiest path for anyone with a keyboard - hand a model a keyword, it scans the internet, blends what it finds, and spits out a hundred-and-first version of an article that already exists in a hundred forms. Google noticed, and they don't like slop, so now they are bringing down the hammer.
However, this will not stop most people from creating content with AI, it will likely just get much harder to compete. So if you are using AI for blog-writing, you need to build a pipeline that forces non-commodity output - a solvable engineering problem.
I built and actively run this flow at multiple at Backbase, where we are producing blogs at scale, competing in a dense, well-funded content space. Some of it comes from CXL, where I set up a similar flow with a lean team built one of the most trusted editorial libraries in marketing. In both places, the transcript was everything. If you have a good set of transcripts, get the brief right and the content that follows is non-commodity by design.
---
What makes content non-commodity
Here are five things that make a piece of content something only your brand could have published.
Point of view:
A perspective no one else has - it comes from your experience, your data, your market position. This cannot be manufactured by scanning the internet - it has to come from somewhere real. Ai is not great at making things up out of thin air. Do not underestimate a strong POV coming from a brand with authority.
Proprietary insight from spoken word:
Podcast transcripts, webinar recordings, and voice notes from a subject matter expert inside the business who knows things the internet does not. The structure stays the same. What changes is one well-placed line: "In a recent conversation with [name], this came up" or "Across our work with 120 clients, we see this consistently." That single anchor pulls the whole piece back to lived experience, and a well-placed line like that signals real knowledge without touching anything else.
Proprietary data
A study or unique product and user data that you have that no one else has access to. Something you can bring to the internet that has not been placed there before and cannot be made up.
The AI snippet angle:
This is the newest lever and the most powerful one. Google's AI snippet summarises the top sources on a given query and cites them. That is useful to us. You can analyse the snippet, pull the cited URLs, scrape them, and let AI identify what your brand brings that none of those sources reflect - a specific point of view, proprietary data, a framing your brand has earned the right to own. That becomes the brief.
Writing from that angle:
You are writing the thing that does not exist yet in the cited sources - the piece that only your brand could have produced, grounded in your knowledge base.
---
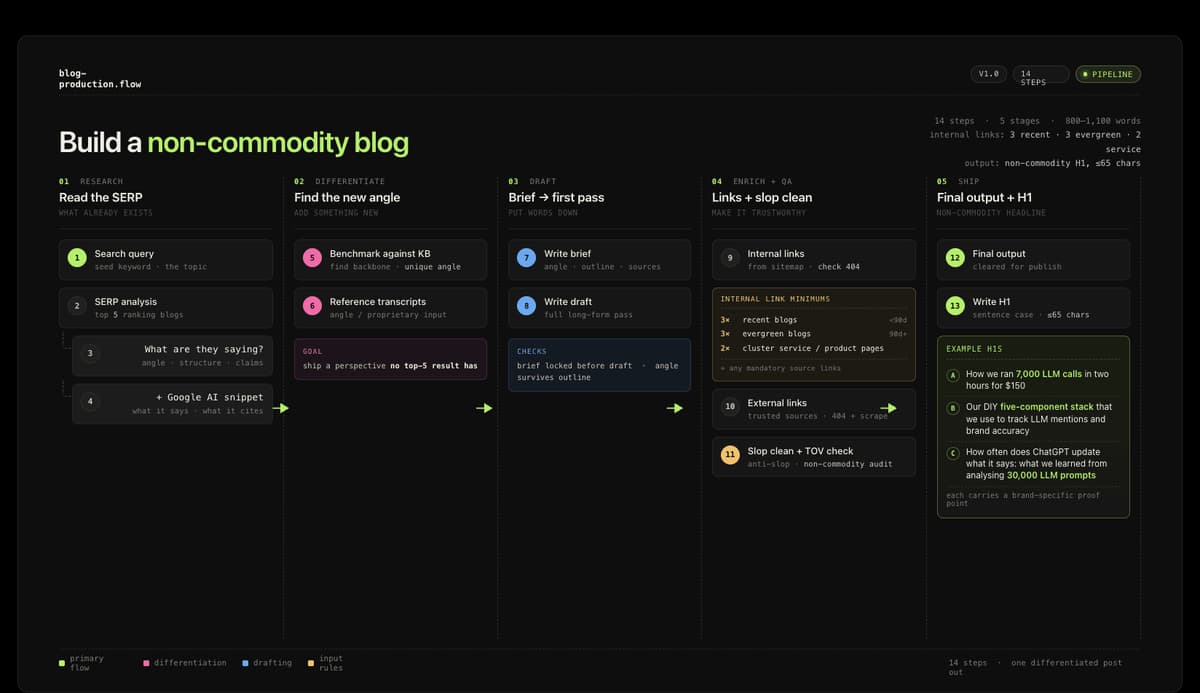
The pipeline, step by step
This is the updated flow, built around forcing non-commodity output from the brief stage upward.
Step 1 - Seeded search query. The topic comes in, either as a keyword or a prompt. Standard starting point.
Step 2 - SERP analysis. Pull the top five ranking articles, scan what they cover, note the structure and subtopics. This step has not changed. What they are saying is still useful context - you need to know the baseline before you can exceed it.
Step 3 - AI snippet pull. This is new. Pull the Google AI snippet for the query. Two questions: what is it saying, and what URLs is it citing? The snippet is Google's own synthesis of what it considers the most comprehensive answer. That is the ceiling you need to write above.
Step 4 - Identifying your brand's uncovered angle. Benchmark the snippet and every cited URL against your own knowledge base. What does your brand know, or what position does your brand hold, that is distinct from what those cited sources cover? Don't treat this as a vague creative exercise - it is a structured comparison. The output is a specific angle or claim that is genuinely absent from the SERP. AI is surprisingly good at this, given that your knowledge base is well set up.
Step 5 - The brief directive. That angle is now the instruction. Give the model "write about AI in banking from this specific angle that no cited source has covered, grounded in this knowledge base context." The rest of the brief builds from there.
Step 6 - Transcript reference for proprietary insight. Check the transcript library. Is there something a real person said - in a podcast, a webinar, a voice note, or do we have data in a study or product insights - that supports or sharpens that angle? A quote from a founder, a line from a client conversation, a stat from an internal implementation - anything that anchors the piece in lived experience. If it exists, it goes in.
A podcast from early 2025 is already stale in a space moving this fast - keep the library clean and current, and strip anything that does not apply to the specific topic out of context entirely.
Step 7 - Write the brief. The brief now carries four inputs the standard brief never had: the AI snippet analysis, the specific angle directive grounded in your brand's knowledge, the transcript quote or reference to include, and the explicit instruction to write above the existing SERP ceiling. The model writes from all four.
Step 8 - First draft. The AI writes from the brief, the knowledge base, and the proprietary inputs. Structure, argument, supporting evidence - all from the inputs.
Step 9 - Internal linking. Links placed directly from your sitemap, varied as active (non-404), based on the topical authority map and rules like "3 new blogs, 3 evergreen high-performers, 2x related cluster product/service pages."
Step 10 - Structural clean and slot check. Tighten structure, verify the non-commodity angle landed, check URL for cannibalization.
Step 11 - Slop clean, hard rule and POV enforcement. What you have up until here is great, but it's also a significant amount of tokens and context. LLMs often miss small things like banned words on the big pass and initial draft. This forces those rules into the final draft without losing context.
Step 12 - Final draft output + non-commodity H1. This has to come at the end so it doesn't suck. AI is really bad at writing headlines if it doesn't have the context from the previous steps here.
Step 12 - Human review. The editor reads, approves or refines. A sharp editor will catch when a brief's brand angle didn't survive the model's draft intact - and fix it before it ships, or simply rerun the flow.
---
The spoken word system - where this is heading
The transcript reference step only works if the transcript library is current and genuinely useful. That is a manual curation problem. Give a subject matter expert - a founder, a senior practitioner, anyone who speaks with authority on the topic - a frictionless way to brain dump by voice. They record a note, it routes into the system, and it becomes immediately available as a knowledge base input for any blog that touches that topic. The more they speak, the more the system sounds like them. We build this directly into our system, so the top experts can easily provide us with the input we need to turn it into content. The more spoken word we have, the better.
The infrastructure is straightforward, but building the habit is sometimes a bitharder. I'll even send the subject matter experts scheduled emails on Monday mornings to remind them to do a voice note brain dump. Build the pipeline steps now, test the flow with the transcripts that exist, and treat spoken word capture as a priority.
---
What this changes about the brief
A non-commodity brief looks structurally similar to any other brief - same headers, same word count, same internal linking logic, same output structure and template. The instruction it carries is what does the work.
The non-commodity brief carries the brand's uncovered angle and knowledge base context - plus a grounded reference, a line from a real conversation or proprietary data that anchors the point, before any actual drafting happens.
The pipeline can be built to run this automatically. Most of the steps already exists in a standard SEO blog flow. What this adds is the snippet analysis and the brand angle directive - two inputs in the brief stage that change everything the model does with the instruction, because they force the output to come from somewhere only your brand can stand.
Shout if you have questions or need help setting this up.