Claude Fable 5 for content marketing: what it actually changes
Claude Fable 5 is the most capable model Anthropic has ever made publicly available. It runs longer, reasons harder, and handles vision and multi-step work at a level that previous Claude versions couldn't sustain. For content teams - especially small ones - that's a meaningful step up, provided you know where to point it.
What Claude Fable 5 is and what it means for content work
Claude Fable 5 is Anthropic's new flagship model, available to everyone starting 9 June 2026. It shares the same underlying architecture as the restricted Claude Mythos 5, wrapped in safety classifiers that make it suitable for general use. Pricing sits at $10 per million input tokens and $50 per million output tokens, with a 90% prompt-cache discount on inputs when you load your brand guidelines, personas, and style rules once and reuse them across sessions. For a small team, that changes everything about the economics.
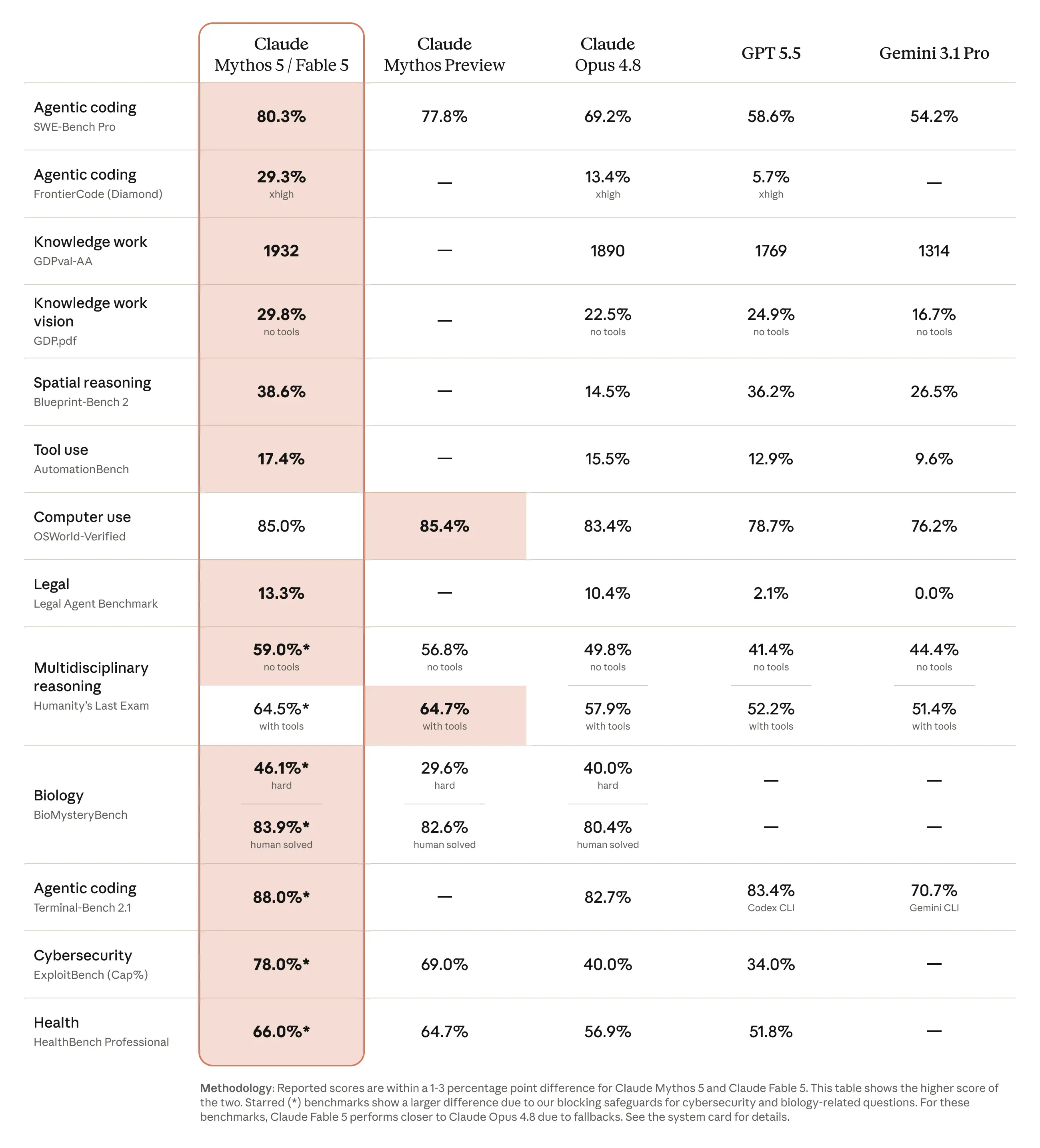
The benchmark that stands out for content work is Fable 5's performance on Anthropic's own knowledge-work evaluation, where it tops the table - and that's backed up across the other published benchmarks too. Stripe ran early tests and reported that Fable 5 compressed months of engineering work into days. That's a software story, but the underlying capability - long-running autonomous work, self-verification, sustained context over complex multi-step tasks - translates directly into content operations. The longer and more complex the task, the bigger the lead over previous models.
For content engineering work specifically, four capabilities separate Fable 5 from what came before: it holds context across genuinely long tasks without degrading, it reads and interprets charts and tables embedded in PDFs and images, it self-verifies its output against the goals you give it rather than just completing a task and stopping, and it handles delegated multi-step work with real autonomy - research, drafting, and iteration without a human prompting each stage. These are the capabilities that pay off when you're pulling data from PDFs straight into a whitepaper draft, or running a full research-to-publish workflow in a single pass.
Long-form content and research pipelines
Where Fable 5 earns its keep in a content operation is in tasks that previous models would quietly fall apart on halfway through. Long-form whitepapers, pillar pages, detailed editorial briefs drawn from multiple sources - these are exactly the kind of sustained, multi-step jobs the model was built for. Earlier Claude versions would start strong and lose coherence somewhere around the 4,000-word mark. Fable 5 holds the thread.
The practical workflow looks like this: you load your brand knowledge base once using prompt caching, then run research, synthesis, and drafting as a single connected task rather than a chain of separate prompts you stitch together manually. The 90% cache discount on inputs makes this economical. I've watched teams slash their per-piece production time by loading a single well-structured knowledge base and letting Fable 5 run the full draft without a handoff in sight.
Content Marketing Institute's agentic content workflow thinking describes exactly this kind of setup - systems where agents hold context and hand work off with clear roles. Fable 5 is the first Claude model with enough sustained capacity to run those systems without a human patching the gaps every few steps.
Vision capabilities and data-driven content
Fable 5's vision features are more useful for content work than they first appear. The model reads diagrams, charts, tables, and infographics embedded in files and PDFs with enough accuracy to use as a primary source, rather than a secondary check. That opens up a workflow that was previously painful: you hand the model a data report, a competitor teardown, or a market research PDF, and it pulls the relevant figures and builds content around them directly.
For a content team that regularly turns data into blog posts, social threads, or newsletter sections, this removes one of the most time-consuming manual steps. You're not retyping tables or describing charts in prose before the AI can use them. You give it the file, set the goal, and let it interpret and write from the source material. When the output needs checking, the model has already run a self-verification pass against what you asked for - which means fewer obvious errors to catch on first review.
Agentic campaign work: what's realistic in 2026
A lot of the Fable 5 coverage leans hard on "agentic campaign building" as though it means you hand the model a brief and walk away. The reality is more useful and more specific than that. Fable 5 handles delegated tasks with real autonomy - it can research, draft, self-check, and iterate without needing a human to prompt each step. What it can't do is replace the strategic judgement that decides what to build in the first place, or the editorial judgement that decides whether the output is worth publishing.
Fable 5 handles the execution leg of your content operation. You define the goal, the audience, the format, the constraints. It does the sustained work - the research passes, the drafting, the reformatting for different channels, the SEO structure. Six months ago, running that kind of workflow reliably required either a serious technical setup or a very patient editor patching model output at every stage. Understanding how agentic content workflows are actually structured helps set expectations for where the model fits in.
Prompt caching: the underrated practical detail
The 90% input token discount from prompt caching is the Fable 5 feature that gets the least coverage and probably delivers the most value in day-to-day content work. The idea is simple: instead of re-sending your full brand guidelines, style rules, audience profiles, and editorial standards with every prompt, you cache them once. The model loads them from cache on subsequent calls at a fraction of the cost.
At full price with no caching, $10 per million input tokens adds up fast if your brand context alone runs to several thousand tokens per call. With caching active, the input cost drops to roughly $1 per million tokens on cached content.
For creating on-brand content with AI consistently, this is the setup detail worth getting right before anything else. Load the knowledge base once, cache it properly, then run your workflows against it. The output improves because the model has full context every time, and the cost stays manageable.
What Fable 5 doesn't change
Fable 5 is a significantly better model. It does not fix the problem of a weak brief, a thin knowledge base, or a workflow with no quality control built in. The model's self-verification step only works against a clear goal - give it a vague one and the verification pass has nothing solid to check against, so sharpen the brief before you run the workflow. Anthropic's own guidance on goal-setting for agentic tasks is worth reading before you build anything serious around this feature.
Fable 5 comes with safety classifiers that route certain sensitive queries to Opus 4.8 instead. Anthropic is conservative with the thresholds and the classifiers fire on less than 5% of sessions on average, but for content teams working in areas like cybersecurity, health, or regulated industries, there may be occasional friction. For the work that the vast majority of content marketing in the age of AI involves - editorial, research, SEO, repurposing, social - the safeguards are essentially invisible.
The 2026 content marketing trends research from Content Marketing Institute describes 2026 as the year agentic workflows and content operations come together for real. Fable 5 is the model that makes that timing credible. The capability is there. The question for each team is whether the workflow is set up to use it properly.
How to start using Fable 5 in a content operation
Access is available through the Anthropic API (model ID: claude-fable-5) and through Amazon Bedrock and the Claude Platform on AWS. For a non-technical content operator, the most practical route is a platform that already has the model integrated and the workflow infrastructure built - rather than building API calls from scratch.
The difference between the Claude API and Claude chat for marketing work is substantial. The API, wired into a proper workflow, gives you a content operation with real autonomy behind it, while the chat interface gives you capable assistance on demand. The operational advantage shows up in repeatable workflows, not one-off prompts - the ones that run the same way every time, with your brand context loaded and your output standards built in from the start.
The non-commodity content playbook is worth revisiting here, because Fable 5 is available to everyone. The workflow, the knowledge base, and the editorial standards built around the model are the competitive advantage.
Frequently asked questions
What is Claude Fable 5 and when did it launch?
Claude Fable 5 launched on 9 June 2026 as Anthropic's most capable generally available model. It shares the same underlying architecture as Claude Mythos 5, the restricted model deployed for vetted cybersecurity and infrastructure partners, but includes safety classifiers for general use. It's available via the Anthropic API with model ID claude-fable-5, through Amazon Bedrock, and on the Claude Platform on AWS. Pricing is $10 per million input tokens and $50 per million output tokens.
How does Fable 5 differ from Claude Opus 4.8?
Fable 5 scores 80.3% on SWE-Bench Pro versus 69.2% for Opus 4.8, and outperforms it on nearly every published knowledge-work benchmark. The practical differences for content work are that Fable 5 sustains coherence over much longer tasks, handles vision inputs like embedded charts and PDFs, and self-verifies output against stated goals. The longer and more complex the task, the larger the lead over Opus 4.8.
What does the 90% prompt caching discount mean in practice?
When you cache your brand guidelines, audience profiles, and style rules using Anthropic's prompt caching, subsequent calls that draw on those cached inputs are charged at roughly 10% of the standard input token rate. For a content team running Fable 5 at any real volume, this is the setup detail that keeps costs manageable. Without caching, loading a full brand knowledge base on every call adds up quickly. With it, input costs on the cached portion drop to approximately $1 per million tokens.
Can Fable 5 run fully autonomous content campaigns?
Fable 5 can handle genuinely autonomous execution of multi-step content tasks - research, drafting, reformatting, and self-verification - without needing a human to prompt every step. What it can't replace is the strategic judgement that defines what to build, or the editorial review that decides whether the output is worth publishing. The model handles the sustained execution leg of a content operation; the human still sets the goals and checks the output before it ships.
Does Fable 5 work well for small teams and solo founders?
Yes, and the economics are better than they look at first glance. The prompt caching discount makes running Fable 5 against a consistent brand context affordable at real content volumes. For solo founders and one-person marketing teams, the model's ability to sustain long tasks and self-verify output reduces the editing and patching work that previously made AI-assisted content production slower than it should have been. The setup still matter - a strong knowledge base and a clear workflow produce significantly better results than a bare API call.